TSQL group_concat workaround
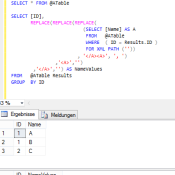
Die Funktion group_concat gibt es in Windows-Azure TSQL nicht. Es gibt allerdings Szenarien in denen diese Funktion evtl. sinnvoll ist. Man kann sich mit „XML PATH“ behelfen: DECLARE @ATable TABLE ( [ID] INT, [Name] CHAR(1)) INSERT INTO @ATable VALUES (1, ‚A‘) INSERT INTO @ATable VALUES (1, ‚B‘) INSERT INTO @ATable VALUES (2, ‚C‘) SELECT * FROM @ATable SELECT [ID], REPLACE(REPLACE(REPLACE( (SELECT [Name] AS A FROM @ATable WHERE ( ID = Results.ID ) FOR XML PATH (“)) , ‚</A><A>‘, ‚, ‚)
